Nell’ottobre del 2018, presso la casa d’aste Christie’s, viene venduta un’opera destinata a far discutere. Ritrae un uomo vestito di nero, con un elegante colletto bianco e un’aria pensierosa. Nella parte inferiore del quadro, anziché la firma dell’autore, è presente una formula matematica, più precisamente l’algoritmo che ha generato il contenuto. L’opera in questione, “Edmond de Belamy”, è stata creata Obvious, un collettivo composto da tre giovani ragazzi francesi. È la prima volta che un’opera creata mediante un’intelligenza artificiale viene messa in vendita sul mercato dell’arte mondiale.
Negli ultimi anni, l’interesse verso questo nuovo modo di fare arte è in costante aumento, con la conseguente fioritura di ricerche e sperimentazioni sugli algoritmi che ne permettono la creazione.
L’arte prodotta con l’AI (Artificial Intelligence), possiede la peculiarità di essere “computer generated”, a significare che il programma utilizzato possiede una parte autonoma nella creazione, non controllata dall’essere umano (quest’ultima si differenzia dalle opere “computer assisted”, in cui il programma -es. Photoshop - rappresenta semplicemente un mezzo del quale l’artista si serve per creare).
Questo processo di creazione è permesso dalle GAN (Generative Adversarial Networks – Reti Antagoniste Generative), ideate nel 2014 da Ian Goodfellow. In termini tecnici, le GAN sono composte da due strutture, o, in altre parole, da due intelligenze artificiali, il discriminator e il generator, i quali lavorano dato uno specifico training set, ovvero un insieme di dati (nel nostro caso, di immagini) predisposte per addestrare la rete. Il generator traspone un vettore di valori di input in un’immagine di output idealmente simile al tipo di immagini osservate nel training set, pur non costituendone una copia. Il discriminator, invece, riceve le immagini di input (sia i campioni reali che i fake generati dal generator) ed effettua una serie di trasformazioni, producendo un output numerico.
Nello specifico, è addestrata a restituire un numero compreso tra 0 e 1 che indica la misura in cui ritiene che l’immagine di input sta “vera” (cioè verosimilmente tratta dai dati usati per l’addestramento) o meno. L’addestramento delle GAN si svolge tra questi due modelli, ciascuno dei quali non può visualizzare direttamente i valori di riferimento dell’altro; via via che il discriminator migliora lentamente le sue capacità di distinguere le immagini reali da quelle prodotte dal generator, quest’ultimo, a sua volta, migliora lentamente la sua capacità di creare immagini di cifre in grado di ingannare il discriminator.
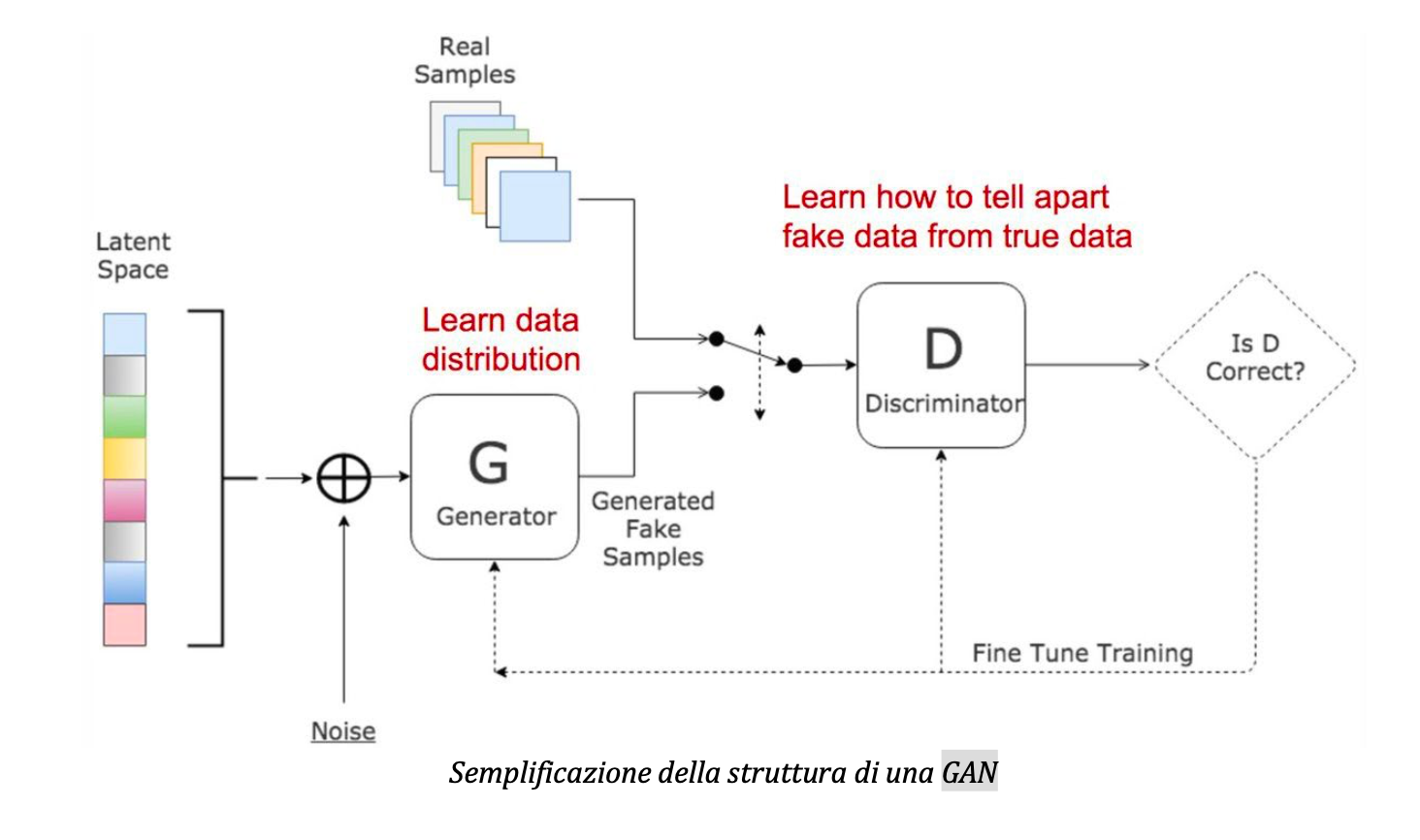
Il modello generativo si può considerare simile a un gruppo di falsari che tentano di produrre banconote false e di utilizzarle senza essere scoperti, mentre il modello discriminativo è simile alla polizia, che tenta di individuare le banconote contraffatte. Il generator, non avendo accesso al training set, cerca di avvicinarsi ad esso procedendo a tentoni, grazie al valore numerico generato dal discriminator, il quale indica il livello di “similarità” alle immagini del training set di addestramento. In questo gioco, la competizione spinge entrambi a migliorare i propri metodi fino al punto in cui i falsi risultano indistinguibili dai modelli autentici.
Sul web sono presenti varie piattaforme per conoscere i risultati ottenuti con l’AI, tra cui i siti Bored Humans (https://boredhumans.com/) e Thisxdoesnotexist (https://thisxdoesnotexist.com/).
Quest’ultimo raggruppa una serie di siti ideati da diversi autori che creano elementi (immagini, testi, e musiche) utilizzando le GAN. In particolare, il sito Thisartworkdoesnotexist (https://thisartworkdoesnotexist.com/) ha catturato la mia attenzione: si tratta di una piattaforma che crea opere d’arte moderna astratte e inedite, proposte sottoforma di immagini in formato quadrato, utilizzando un training set composto da dipinti non specificati. Data la natura della psiche umana volta a identificare il contenuto di ciò che visualizza, ho spontaneamente ricercato associazioni visive tra le immagini astratte create dalla GAN ed elementi reali e concreti. A questo punto è nata in me la curiosità di scoprire se esistesse un’intelligenza artificiale, anch’essa in grado di interpretare tali immagini. Il motore di ricerca Google, infatti, possiede la funzione Reverse image research, un sistema di recupero di immagini digitali e fisse (CBIR - Content-Based Image Retrieval Systems), basato su attributi visuali del contenuto delle immagini. Le caratteristiche visuali maggiormente utilizzate da questi sistemi si riferiscono al colore, alla forma e alla texture, le quali permettono alla AI di suggerire un elemento associabile al contenuto, proposto sia sottoforma di immagine che di parola.
La mia scelta si è orientata verso di esso, per via dell’enorme database di elementi visivi di cui dispone e su cui può basare la propria ricerca, fattore che avrebbe fornito una rosa di “parole suggerite” più varia rispetto ad un altro motore di ricerca o applicazione.
Partendo da questa suggestione, ho raccolto 6000 opere generate dal sito “Thisartworkdoesnotexist” e le ho caricate sulla barra di ricerca di Google, il quale ha fornito altrettante parole correlate. In questo modo, le due parti hanno assunto rispettivamente i ruoli di “artista” e “fruitore” che fruga nel proprio database di conoscenze per trovare associazioni visive.
Le immagini sono raccolte in una cartella e rinominate da 1 a 6000 (es. Thisartworkdoesnotexist_0001, Thisartworkdoesnotexist_0002, ecc), mentre la parte testuale è catalogata in un file Excel, in cui, su ogni riga, sono riportati il numero dell’immagine e la parola correlata.
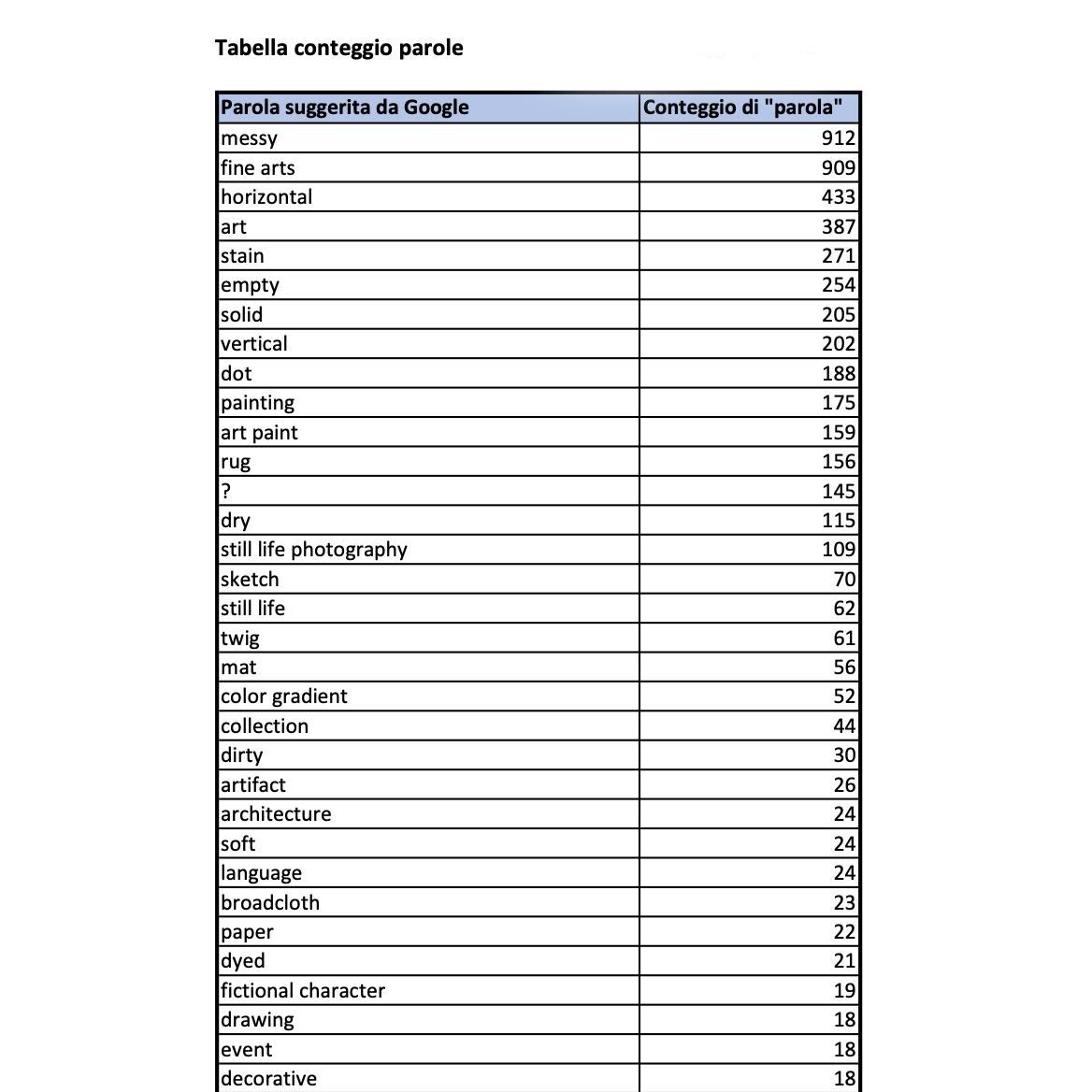
Contrariamente alle mie aspettative, la fantasia di Google è attualmente limitata: l’astrazione delle immagini lo ha messo a dura prova, dimostrando una certa ridondanza, basti pensare che i termini “messy”, “fine arts”, “horizontal”, “art” e “stain” se sommate, ricoprono il 49% dei risultati ottenuti. Si tratta a tutti gli effetti di associazioni generiche e poco originali.
Il lato più interessante della ricerca si concretizza nei restanti risultati, la cui associazione parola- contenuto, mi è parsa curiosa e spesso incomprensibile. Sono emersi molti termini relativi al mondo vegetale e animale e un buon numero di materiali artificiali, ma anche riferimenti alla moda e al cibo fino ad arrivare a nomi di luoghi, di attività commerciali e, più in generale, a concetti astratti.
Per poter estrapolare il numero di volte in cui ogni parola è stata suggerita ho creato una tabella Pivot in Excel, la quale ha filtrato 326 differenti parole. Inoltre, ho creato un’ulteriore tabella riportando le 326 parole con associato il riferimento numerico dell’immagine che le ha generate (per quanto riguarda le parole suggerite più di una volta, il numero dell’immagine correlato è stato scelto in modo puramente casuale - in ogni caso, i singoli riferimenti sono consultabili tramite una ricerca manuale).
Un altro aspetto curioso è scaturito a distanza di giorni dalla ricerca: nella fase di controllo e riordino dell’elenco realizzato in Excel, ho constatato che il motore di ricerca, per alcune parole, proponeva suggerimenti diversi rispetto alla prima ricerca, come se avesse cambiato idea, probabilmente per via di un aggiornamento del proprio database di immagini che detta la scelta del termine da attribuire. Un simile meccanismo accade anche nella mente umana, la quale acquisisce (e, talvolta, perde) informazioni, che, a loro volta, dettano aggiornamenti sul nostro il modo di pensare e agire.In conclusione, sarebbe interessante interrogare Google, con le medesime immagini, ad intervalli di tempo scanditi, ad esempio ogni anno, per documentarne gli sviluppi dettati dagli aggiornamenti avvenuti all’interno del database, con la speranza che, col tempo, (e quindi con un maggior numero di immagini a sua disposizione), acquisisca altrettanta sofisticatezza e precisione nell’effettuare le associazioni.
Nella cartella al link di cui sotto sono presenti i seguenti documenti:
A1. Documento PDF - Ricerca sull’interpretazione di immagini “computer generated” da parte di un’intelligenza artificiale
B1. Elenco completo parole
B2. Tabella conteggio parole (per consultare il numero di volte in cui ogni parola è stata suggerita)
B3. Elenco 326 parole + numero immagine di riferimento (per effettuare un confronto parola/immagine)
C1. Cartella immagini contenente tutte le immagini numerate da 1 a 6000
B1. Elenco completo parole
B2. Tabella conteggio parole (per consultare il numero di volte in cui ogni parola è stata suggerita)
B3. Elenco 326 parole + numero immagine di riferimento (per effettuare un confronto parola/immagine)
C1. Cartella immagini contenente tutte le immagini numerate da 1 a 6000

Parasitism

Pink Floyd

Animal migration

Girly

Art Paint

Intrusive rock

Blood

Hô chì minh city museum

Gucci

Transparency

Body modification

Marrakech

Violence

Dot

Banana




